Reducing CMake heap usage part 2: Know your tools
Introduction
At the end of the previous post, after all those optimizations I stated:
For more complex configurations the economy is of course lower. Partly because there’s an old parsing routine that allocates a lot and becomes the major memory consumer.
After a while, I decided to investigate why so much memory is used and found a surprisingly easy way to fix it.
Previous results
Here’re the overall results of previous optimizations(total allocated bytes (number of allocations)):
- empty project: 65 MB (394k) -> 39 MB (280k)
- google benchmark: 233 MB (1344k) -> 196 MB (1190k)
- heaptrack: 305 MB (1308k) -> 268 MB (1148k)
As you can see, not a big improvement for the last two projects. Let’s take a look at heaptrack report of heaptrack itself:
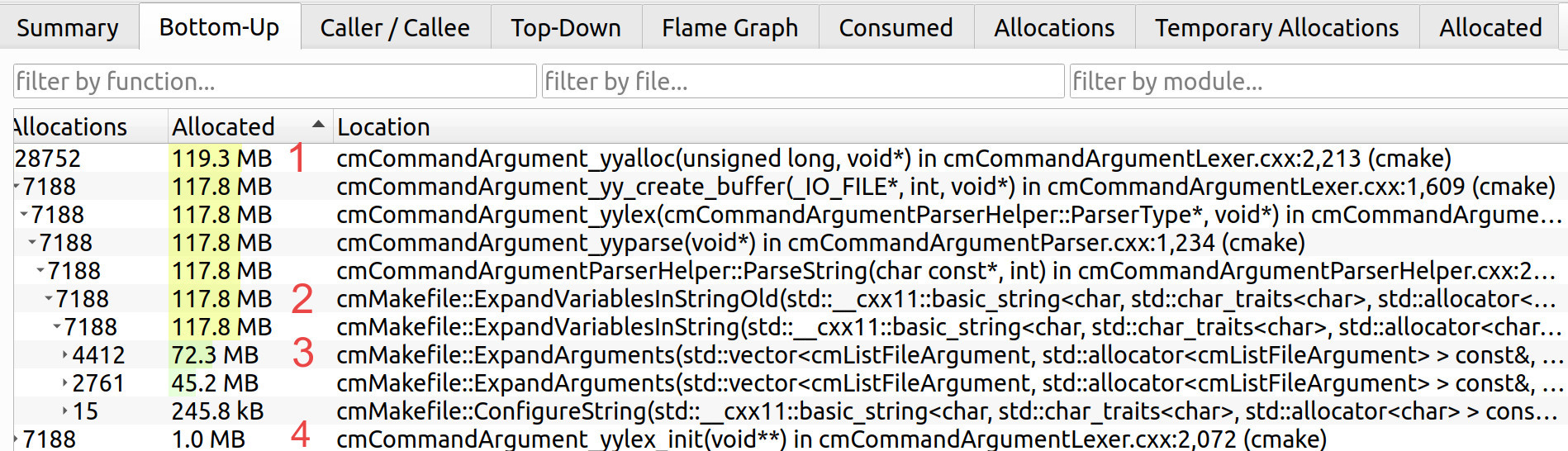
We can see that the top consumer is cmCommandArgumet_yyalloc()(1), it stems
from cmMakefile::ExpandVariablesInStringOld()(2) that in turn stems from
cmMakefile::ExpandArguments()(3). Also, notice the huge difference between
the first(1) and second(4) heap consumers: 119 MB vs 1 MB correspondingly.
What’s going on?
Looking at that report, I had several questions:
- What is
ExpandVariablesInStringOld()? - Why does it eat so much memory?
- Why doesn’t it exist in the report of the empty project?
I’ll answer the (1) and (3) first, then the (2).
Argument expansion
Argument expansion is a process of replacing variable reference(${var}) with
variable’s value(var_value) and, for unquoted arguments, replacing
list(a;b;c) with its elements as separate arguments(a, b, c). CMake does
this for every argument of every command call using ExpandArguments(),
so this function is called pretty frequently.
Variable references could be nested and mixed with plain
strings(ab_${cd_${ef}}_$ENV{env_var}), the algorithm for their expansion is
not so trivial. CMake uses Flex scanner and Bison
parser to do this, the driver function to run them is called
ExpandVariablesInStringOld().
Why old? Because that was the case before CMake 3.1. Back then, Flex/Bison
implementation was considered to be slow and inefficient(which is strange
because these tools are used for decades) and the whole thing was
replaced with hand-crafted
implementation(cmMakefile::ExpandVariablesInStringNew()).
Old vs. new
If it was replaced in CMake 3.1 then why was it used in CMake 3.18 when I
configured google benchmark and heaptrack? Because of the cmake_minimum_required()
command. Roughly speaking, when you set a minimum required version for your
project, CMake adjusts its behavior to that version. So, if you call it with
anything below 3.1, CMake will use ExpandVariablesInStringOld().
Heaptrack calls cmake_minimum_required(VERSION 2.8.12) and google benchmark
includes google test which calls cmake_minimum_required(VERSION 2.8.8).
The problem
Now, we can reproduce that enormous heap consumption with empty project:
cmake_minimum_required(VERSION 2.9)
project(empty)
Heaptrack report is quite similar to the above one:
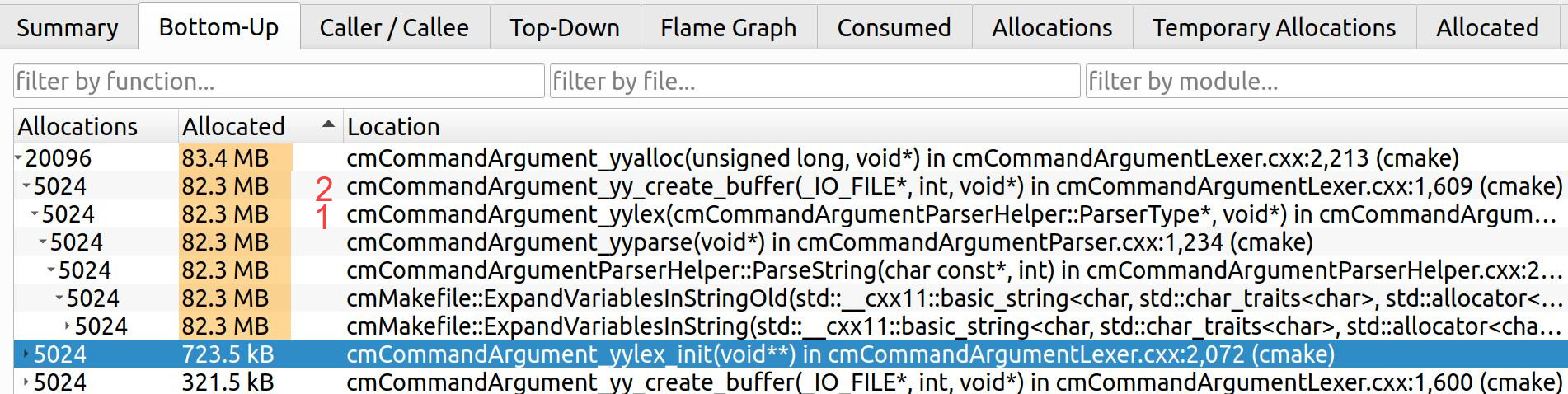
Here and further I’ll omit cmCommandArgument_ part of function names, that’s
just a prefix to avoid name clashes.
We can see that yylex()(1) allocates a lot of memory using
yy_create_buffer()(2). FYI, yylex()(Flex part) is responsible for reading
the input and returning the token to yyparse()(Bison part).
Here’s the troublesome part of the yylex() code:
#define YY_BUF_SIZE 16384
int yylex()
{
if(!init)
{
yy_create_buffer(YY_BUF_SIZE);
}
//...
}
We can see that Flex allocates 16 KB of memory for whatever purpose. Recall that
ExpandVariablesInStringOld() is called for every argument, thus, Flex
allocates 16 KB of RAM thousands of times, and it doesn’t depend on argument
structure nor its size. Looks pretty bad, huh?
Flex input management
Why does Flex need that buffer? Flex can be configured to take its input from
the file handle(the default is stdin, i.e., the terminal) or from the provided
buffer. When it’s a file handle, obviously, it needs a buffer for the data to be
read, so it allocates 16 KB for that purpose. When it’s configured to read from
the buffer it doesn’t need that additional 16 KB because all data is already
provided. Flex needs mutable buffer, client has a choice: provide a mutable
buffer or allow Flex to make a copy of immutable one. Sounds reasonable?
Arguments are of course located in string buffers, not in file, why,
after all, was that 16 KB allocated? Well, because for whatever reasons CMake
uses the third, kinda tricky, way: it doesn’t configure Flex to read from the
buffer, instead it replaces file reading routine through Flex macro YY_INPUT
with code that do actual read from buffer. Thus, Flex thinks it’s going to
read from file, allocates 16 KB for file buffer, and calls overridden
file reading routine. Arguments are usually small strings, much less than
16 KB, hence we got that huge overconsumption.
The fix
The fix was fairly simple. I replaced all that hackery with the call to
public API yy_scan_string() and everything just worked. Let’s check heaptrack
report:
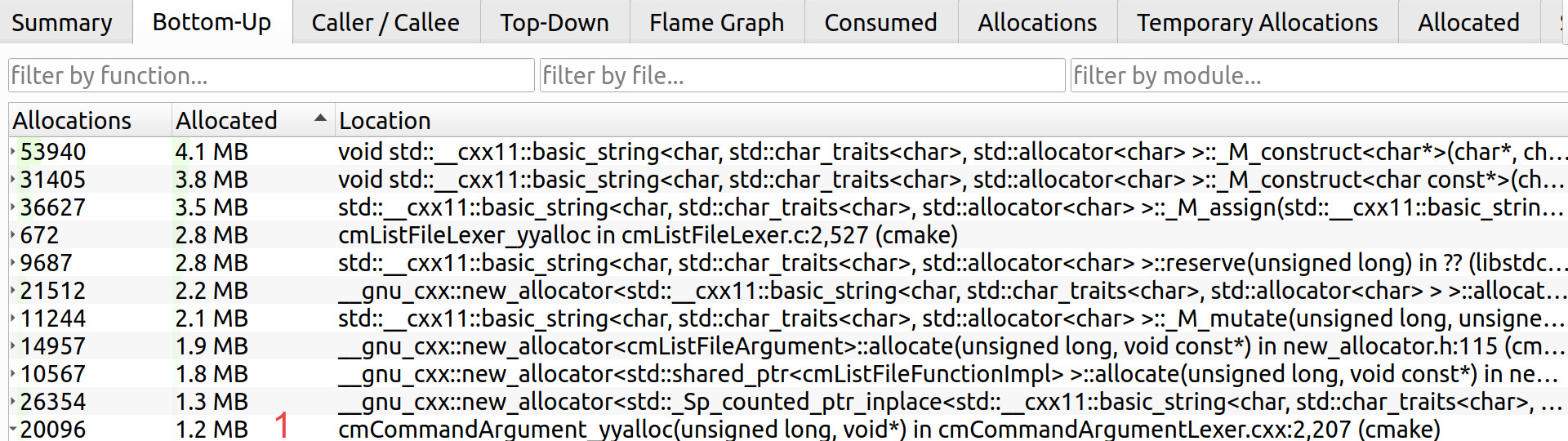
Now, yyalloc()(1) has allocated 1.1 MB instead of 83 MB :)
Overall results(total allocated bytes (number of allocations)):
- empty project: 120 MB (354k) -> 38 MB (351k)
- google benchmark: 233 MB (1344k) -> 137 MB (1153k)
- heaptrack: 305 MB (1308k) -> 140 MB (1113k)
Benchmark
Like I said before, I was surprised that Flex/Bison solution was replaced by
hand-crafted parser due to the poor performance of the former. So I decided to
do a little benchmark of three methods: old ExpandVariablesInStringOld(), new
one, and hand-written ExpandVariablesInStringNew(). I used this simple
file:
# cmake_policy(SET CMP0053 OLD) # use ExpandVariablesInStringOld()
cmake_policy(SET CMP0053 NEW) # use ExpandVariablesInStringNew()
function(sink)
endfunction()
foreach(i RANGE 1000000)
sink(simple_var ${simple_var_ref} ${nested_${var_${ref}}})
endforeach()
It’s main purpose is to generate a lot of argument expansion calls. Measurement was done with
/usr/bin/time -v cmake -P bench.cmake
Results:
- hand-written
ExpandVariablesInStringNew(): 4.53 sec - new
ExpandVariablesInStringOld(): 5.38 sec - old
ExpandVariablesInStringOld(): 12.71 sec
So yes, the old version was really slow, and had to be replaced. But was it slow due to Flex or Bison problems? Of course no. Actually, I suppose that if the old version had been done right, nobody would have thought about its replacement. Yes, it’s still slower by ~20% than the hand-written version, but this difference isn’t noticeable in real-world cases. Not to mention how easier it’s to understand and maintain Flex/Bison specs compared to hand-written code.
Conclusion
Know your tools, don’t reinvent the wheel. Widely used tools usually have all the needed APIs for nearly all common use-cases. If you find that it doesn’t fit your needs, consider you’re doing something wrong. Think hard to comprehend the problem, then learn what tool provides. And only when you understand them both, you can use some hacks or custom solutions.